How I made a Cocktail Recommendation App Using Machine Learning with Python, Streamlit, Airtable...
section-content
section-content
How I made a Cocktail Recommendation App Using Machine Learning with Python, Streamlit, Airtable, and GPT-3.
Part 1 --- The Intro
Try the app here

I was at a bar trying to discover new combinations of flavors that I could enjoy, but it was rather difficult to rely on the bartender's guess since I only have two or three drinks to try before heading home. What if I don't enjoy them? I have to be very careful in picking the drinks to spend the night pleasantly. This got me thinking, what if there was a way to find cocktails that I could enjoy with the flavors I already know I enjoy?
I decided to create a cocktail recommendation app using machine learning that would take in a list of features of a cocktail that I enjoy and recommend cocktails that could increase the likelihood of me enjoying them.
My original idea is to cluster the cocktails based on the ingredients and some engineered features such as the presence of liqueur, then create an arbitrary cocktail with selected features that the user enjoys, and classify it to the cluster of most related cocktails to further spit up the cocktails from that cluster as recommendations.
section-divider
section-content
Part 2 --- The Dataset
To create this app, I first needed to find a dataset of cocktails and their ingredients. I found a great dataset on Kaggle that contained over 600 cocktails and their ingredients.
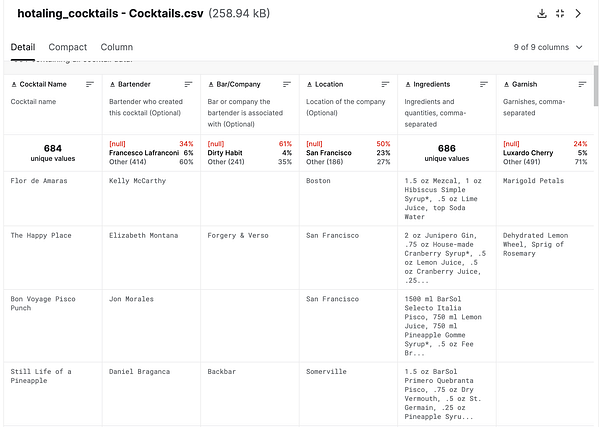

The dataset turned out to be quite informative as it contained the ingredients and preparation instructions for the cocktails which would simplify the job for the bartender as well as give me an idea about how to approach the problem.
As you can see there are quite a few missing values for the names of the cocktails, but that is not important as long as we have the ingredients and IDs for the items.
I will be using GPT-3 to generate the names of missing names of the cocktails

Next, I created a list of ingredients that make up flavor profiles and assigned a boolean for the flavor to each cocktail



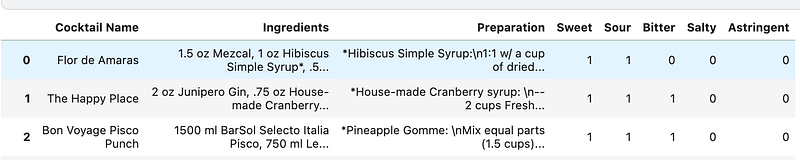
Then I did the same thing for the base alcohol and the presence of liqueurs.

Now I have a prepared dataset for my machine learning model and can upload it to airtable.
section-divider
section-content
Part 3 --- The Algorithm
I will be training two algorithms on my dataset:
- [K-Means Clustering to cluster the cocktails based on their ingredients]
- [Neural Network because it performs best(see code below)]
The reason I chose K-means is that it is an unsupervised method which means that I don't need labeled data to train them. This is important because it would be very difficult to come up with arbitrary groupings for all 600+ cocktails by hand unless you base them on the base alcohol. Then the problem arises that we are limiting ourselves to only the drinks with the same alcohol but different taste profiles, which is not what we want. K-Means Clustering is a good choice for this problem because it groups similar objects together and we can use that to our advantage by finding groups of cocktails with similar ingredients which should theoretically taste similar as well.
After I come up with arbitrary clusters, I can use a simple k-nn algorithm to classify a new datapoint.
First, let's select only the most important features to reduce dimensionality. To do that, I will be utilizing Principal Component Analysis (PCA) with 95% variance

And here is how many of these 19 features will come in useful with 95% variance:
from sklearn.decomposition import PCA
pca = PCA(n_components = 0.95)
pca = PCA().fit(train_df)
import matplotlib.pyplot as plt
def plot_pca(pcam, train_df):
plt.rcParams["figure.figsize"] = (12,6)
fig, ax = plt.subplots()
xi = np.arange(1, len(train_df.columns)+1, step=1)
y = np.cumsum(pcam.explained_variance_ratio_)
plt.ylim(0.0,1.1)
plt.plot(xi, y, marker='o', linestyle='--', color='b')
plt.xlabel('Number of Components')
plt.xticks(np.arange(0, 21, step=1)) #change from 0-based array index to 1-based human-readable label
plt.ylabel('Cumulative variance (%)')
plt.title('The number of components needed to explain variance')
plt.axhline(y=0.95, color='r', linestyle='-')
plt.text(0.5, 0.85, '95% cut-off threshold', color = 'red', fontsize=16)
ax.grid(axis='x')
plt.show()

The next step is figuring out how well our clustering algorithm worked, for that, I will use an average silhouette coefficient of 0.55
Silhouette Coefficient:
The silhouette coefficient or silhouette score is a metric used to calculate the goodness of a clustering technique. Its value ranges from -1 to 1.
1: Means clusters are well apart from each other and clearly distinguished.
0: Means clusters are indifferent, or we can say that the distance between clusters is not significant.
-1: Means clusters are assigned in the wrong way.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
def find_clusters(train_df):
range_n_clusters = range(2,200,1)
scores =
for n_clusters in range_n_clusters:
## Initialize the clusterer with n_clusters value and a random generator
## seed of 10 for reproducibility.
clusterer = KMeans(n_clusters=n_clusters, random_state=10)
cluster_labels = clusterer.fit_predict(train_df)
## The silhouette_score gives the average value for all the samples.
## This gives a perspective into the density and separation of the formed
## clusters
silhouette_avg = silhouette_score(train_df, cluster_labels)
print(
"For n_clusters =",
n_clusters,
"The average silhouette_score is :",
silhouette_avg,
)
scores.update()
if silhouette_avg > 0.56:
break

## !! Get the indices of the points for each corresponding cluster
mydict =
df['Cluster'] = 0
for row in df.index:
for key, items in mydict.items():
if row in items:
df['Cluster'][row] = key
Let's analyze the cluster number 7 and see what is going on in there
df[df['Cluster']==7].loc[:,'Sweet':'Cluster']


In this part, we will be training different classification algorithms to see which one performs best.
test_scores.plot(kind = 'scatter',
x = 'Model',
y = 'Score',
color = 'red')
## set the title
plt.title('ScatterPlot')
## show the plot
plt.show()

Part 4 --- Streamlit Layout
First of all, I created a project folder and initiated streamlit in pipenv:
pipenv shell
Then, I created an app.py file and started with importing all the necessary libraries and setting up the page config:
import streamlit as st
from pyairtable import Table
import pandas as pd
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import NearestNeighbors
import plotly.express as px
import streamlit.components.v1 as components
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
import openai
st.set_page_config(page_title="Cocktail Recommendation", layout="wide")
Here you can see the pyairtable library for communicating with airtable database I created, scikit-learn for algorithm building, and openai library for the missing cocktail name generation.
section-divider
section-content
api = st.secrets["api"]
base_id = st.secrets["base_id"]
openai.api_key =st.secrets["openai_api"]
prompt = str("""Here are the cocktail names and their recipes:\n
Ingredients: 1.5 oz Mezcal, 1 oz Hibiscus Simple Syrup*, .5 oz Lime Juice, top Soda Water
Preparation: *Hibiscus Simple Syrup a cup of dried hibiscus steeping for 30-40 min
Name: Flor de Amaras
Ingredients: 2 oz Junipero Gin, .75 oz House-made Cranberry Syrup*, .5 oz Lemon Juice, .5 oz Cranberry Juice, .25 oz Lillet Blanc, 4 dash Forgery Earth Day Bitters, mist Laphroaig
Preparation: *House-made Cranberry syrup: \n-- 2 cups Fresh Cranberries\n-- 1 cup Sugar\n-- 1 cup Water\n-- 2 Bay Leaves\n-- .25 cup Pink Peppercorns\n-- Half Serrano Chile\n-- 4 Sprigs Fresh Rosemary\n\nAdd all ingredients to a pot and heat thoroughly. Simmer on low until cranberries cook down for 25 minutes. Strain and let cool.
Name: The Happy Place
Ingredients: 1500 ml BarSol Selecto Italia Pisco, 750 ml Lemon Juice, 750 ml Pineapple Gomme Syrup*, .5 oz Fee Bros Lemon Bitters, 1 float Old Vine Zin *Pineapple Gomme:
Preparation: Mix equal parts (1.5 cups) gum arabic with water over high heat until it all mixes and then let cool for a bit. Then you're gonna make a sugar syrup with 2 parts sugar, 1 part water (4 cups water, 2 cups white granulated sugar) in the same manner over high heat until it mixes, and then add the gum syrup to the mix until everything dissolves and what you're left with is a thick gummy syrup that resembles a whole lot of baby batter. Then cut up 1.5 cups of pineapple chunks and add them to the punch, mix in
Name:Bon Voyage Pisco Punch
Ingredients: 1.5 oz BarSol Primero Quebranta Pisco, .75 oz Dry Vermouth, .5 oz St. Germain, .25 oz Pineapple Syrup*, 1 tbsp Vieux Pontarlier Absinthe Francaise Superieure
Preparation: *Pineapple Syrup Equal parts pineapple blended with water and sugar and strained
Name: Still Life of a Pineapple
Ingredients: 1.25 oz Luxardo Maraschino Liqueur, 4 drops Acid phosphate, 2 oz BarSol Primero Quebranta Pisco, .75 oz Luxardo Amaro Abano, .25 oz Luxardo Fernet, 3 dashes Scrappy's Aromatic Bitters
Preparation: 1st glass ingredients: Luxardo Maraschino, Acid Phosphate in 2nd glass ingredients: BarSol Quebranta Pisco, Luxardo Amaro Abano, Luxardo Fernet, Scrappy's Aromatic Bitters
Name: The Bittered Valley
Create an original creative name for the following cocktail:
""")
This part of the code sets up the prompt for the cocktail name generation and pulls up the APIs that I will create during the deployment.
section-divider
section-content
Now, lits define the main functions, they will be stored in cache to be used when called.
@st.cache
## Initiating the open ai gpt-3
def get_response():
return openai.Completion.create(
model="text-davinci-002",
prompt = str(prompt+ "\n Ingredients:\n"+ingredients1+"preparation:\n"+preparation1+"Name: "),
temperature=0.9,
max_tokens=5,
top_p=1,
frequency_penalty=1.5,
presence_penalty=1.5
)
def get_data():
at = Table(api, base_id, 'Cocktails')
data = at.all()
return data
@st.cache
def to_df(data):
airtable_rows = []
for record in data:
airtable_rows.append(record['fields'])
return pd.DataFrame(airtable_rows)
title = "Cocktail Recommendation Engine"
st.title(title)
with st.spinner('Fetching Data..'):
df = to_df(get_data())
df = df.set_index(['Field 1'])
df = df.sort_index()
flavors = ['Sweet', 'Sour', 'Bitter', 'Salty', 'Astringent','Liqueur']
alcohol_types = ['Absinthe', 'Brandy', 'Champagne', 'Gin', 'Mezcal', 'Pisco', 'Rum', 'Sambuca', 'Tequilla', 'Vodka', 'Whiskey', 'Wine']
section-divider
section-content
Let's run the initialization and set up the title screen:
#Title
title = "Cocktail Recommendation Engine"
st.title(title)
#Initialization
with st.spinner('Fetching Data..'):
df = to_df(get_data())
df = df.set_index(['Field 1'])
df = df.sort_index()
flavors = ['Sweet', 'Sour', 'Bitter', 'Salty', 'Astringent','Liqueur']
alcohol_types = ['Absinthe', 'Brandy', 'Champagne', 'Gin', 'Mezcal', 'Pisco', 'Rum', 'Sambuca', 'Tequilla', 'Vodka', 'Whiskey', 'Wine']
section-divider
section-content
This is a simple streamlit layout to choose our features to be added to the main DataFrame for the training:
###Main screen
st.write("This is the place where you can customize what you want to drink to based on genre and several key cocktail features. Try playing around with different settings and try cocktails recommended by my system!")
st.markdown("##")
with st.container():
col1, col2 = st.columns(2)
with col2:
st.markdown("***Choose your Flavor:***")
flavor = st.multiselect(
"",
flavors)
with col1:
st.markdown("***Choose features to include:***")
alcohol_type = st.multiselect(
'Select the alcohols you enjoy',
alcohol_types
)
features = pd.DataFrame()
for word in alcohol_types:
if word in alcohol_type:
features.loc[0,word] = 1
else:
features.loc[0,word] = 0
for word in flavors:
if word in flavor:
features.loc[0,word] = 1
else:
features.loc[0,word] = 0
Our features will be of two sets --- alcohol base and flavor profile.
section-divider
section-content
I decided to leave the algorithm running online so you can see how it works:
#Algorithm
if st.checkbox('RUN'):
with st.spinner('Building an Algorithm, beep bop..'):
train_df = df.loc[:,'Sweet':'Pisco']
pca = PCA(n_components = 12)
reduced_df = pca.fit_transform(train_df)
Kmeans = KMeans(n_clusters = 49)
Kmeans.fit(reduced_df)
mydict = ## !! Get the indices of the points for each corresponding cluster
## Assign the clusters to cocktails
df['Cluster'] = 0
for row in df.index:
for key, items in mydict.items():
if row in items:
df['Cluster'][row] = key
#Train test split
X = df.loc[:,'Sweet':'Pisco']
y = df.loc[:,'Cluster']
X_train, X_test, y_train, y_test = train_test_split(X, y,stratify=y, test_size=0.75, random_state=42)
#Training the classifier
mlpc = MLPClassifier(activation= 'identity', hidden_layer_sizes= 100, learning_rate= 'adaptive', solver= 'lbfgs')
mlpc.fit(X_train,y_train)
df = df.append(features, ignore_index=True)
predicted_cluster = mlpc.predict(df.loc[df.index[-1]:,'Sweet':'Pisco'])
#Results returned
col3 = st.columns(2)
st.header('Cocktails you might enjoy:')
st.write("#"*150)
for index, i in df[df['Cluster']==predicted_cluster[0]].iterrows():
if str(i['Cocktail Name']) == '' or pd.isnull(i['Cocktail Name']):
st.subheader('Cocktail Name:')
response = get_response()
st.write(response.choices[0].text)
else:
st.header('Cocktail Name:')
st.write(i['Cocktail Name'])
st.subheader('Ingredients: ')
st.text(i['Ingredients'])
st.subheader('Preparation:')
st.text(i['Preparation'])
st.write("#"*150)
Outro
The final step is to upload the repository to GitHub and deploy it to Streamlit.
To create a repository on Github:
- [Create a new repository on GitHub by clicking the "New Repository" button on your profile page.]
- [2. Name your repository and add a description, then click "Create Repository".]
- [3. In the top right corner of any page, you should see "+ Add", click this and select "Upload files".]
- [4. Drag and drop or upload files from your computer to start adding content to your repository!]
Then, to bake the app with streamlit:
- [Sign up for a free account at streamlit.io]
- [2. Go to your dashboard and click the " New App" button]
- [3. Name your app and select a region, then click "Deploy App"]
- [In the advanced settings write a TOML format code with secrets (APIs, usernames, and passwords)]
- [Streamlit will automatically generate a unique URL for your app, you can share this with anyone to allow them to view or interact with your app online!]


Written by
Anton Vice