Evaluating Distil-Whisper Models Implementations on MacBook
section-content
section-content
Evaluating Distil-Whisper Models Implementations on MacBook
In the pursuit of enhancing speech recognition capabilities within a suite of applications, it is observed that a significant proportion of computational latency within the AI pipeline can be attributed to the speech recognition step, particularly in "real-time" communication scenarios. This presents a substantial bottleneck, necessitating an empirical investigation into various speech recognition implementations to optimize this process.
Accordingly, the objective of this study is to conduct a comparative analysis of several distilled BERT (Bidirectional Encoder Representations from Transformers) models across multiple dimensions, most notably execution speed and transcription fidelity. Previously, the utilization of the Faster Whisper models on a CPU constituted the standard approach. However, with the advent of Apple's Metal (MPS) backend, there emerges an alternative strategy employing distilled BERT models in conjunction with the Transformers library.
This research aims to empirically evaluate these contrasting methodologies using a small-scale dataset to ascertain their respective efficacies. The overarching goal is to determine the most viable option for integration into future projects, balancing the dual imperatives of operational speed and transcription quality. The findings from this analysis will inform the strategic direction for the deployment of speech recognition technologies within upcoming developmental frameworks.
The Contestants
On one side, I have the Faster Whisper implementation, known for its' efficiency and speed. On the other side is the Transformers(torch) implementation that allows me to use mps as device backend.
The Models in Focus:
- [--- `distil-large-v2`]
- [--- `distil-medium.en`]
- [--- `distil-small.en`]
I utilized the librispeech_asr_dummy
dataset from Hugging Face---a simplified version of the extensive
LibriSpeech dataset, which is a staple in ASR research. This allowed us
to conduct my tests swiftly without compromising the validity of my
findings.
The Evaluation
The evaluation rested on two pillars: the time taken to transcribe an audio sample (speed) and the semantic similarity of the transcribed text to the ground truth (accuracy). Semantic similarity was quantified using cosine similarity measures between sentence embeddings of the transcriptions and the ground truth.
The Showdown
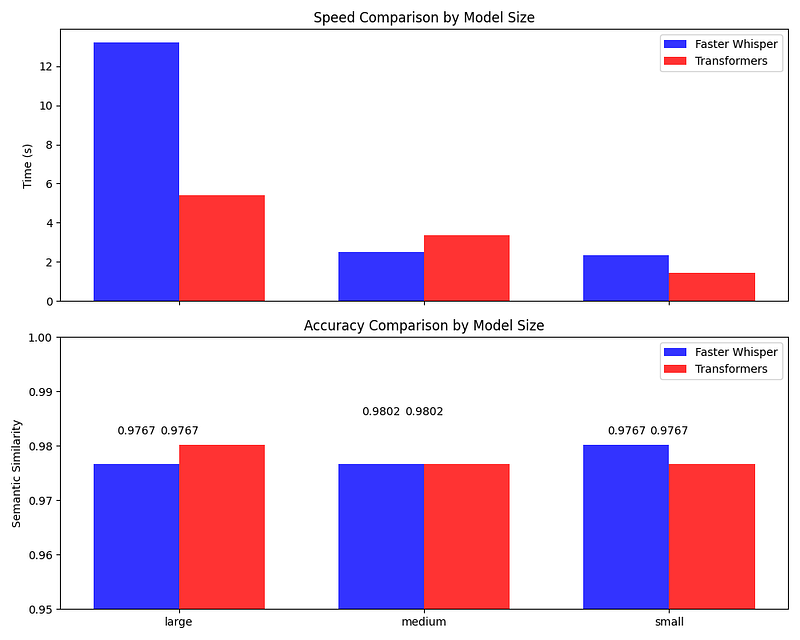
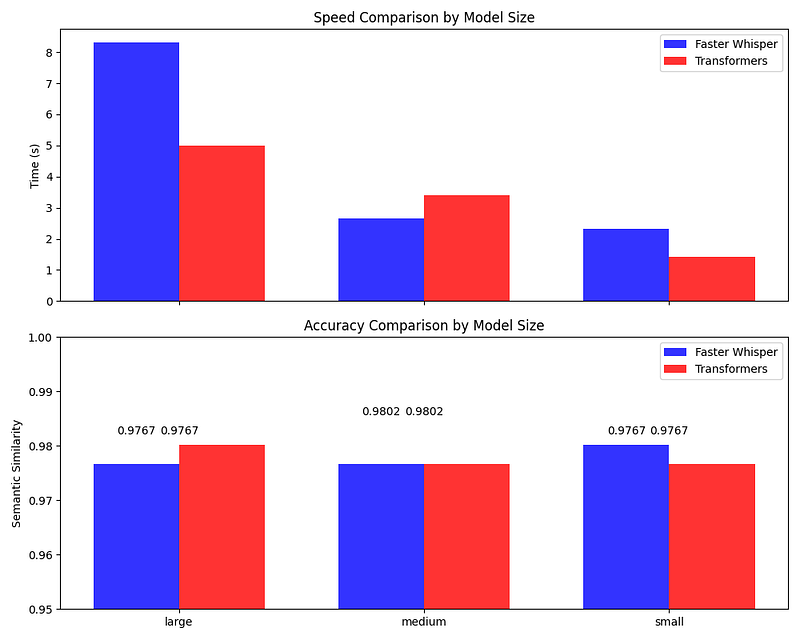
My tests revealed a neck-and-neck race between the two implementations. Here's what I found:
- [Large Models: Faster Whisper had a slight but noticeable advantage in speed, without any significant trade-off in accuracy.]
- [Medium Models: The battle was closer here, with Faster Whisper still edging out in speed.]
- [Small Models: The duel was almost at a draw in terms of speed, but Faster Whisper pulled ahead with a marginally higher accuracy score.]
The Takeaway
My comparison highlighted the Faster Whisper's edge in processing speed, particularly with larger models. If you're operating in an environment where time is of the essence, Faster Whisper could be your go-to choice. However, for applications with strict resource limitations or when deploying on edge devices, the small models from either family are commendable contenders.
Behind the Scenes
How did I arrive at these conclusions? My project was meticulously
designed to ensure fairness and accuracy. I used the latest tools and
techniques, including Hugging Face's datasets library for loading the dataset and the
sentence-transformers library to
calculate semantic similarity.
sentence_model = SentenceTransformer('all-MiniLM-L6-v2')
def calculate_semantic_similarity(ground_truth, transcription):
ground_truth_embedding = sentence_model.encode(ground_truth, convert_to_tensor=True)
transcription_embedding = sentence_model.encode(transcription, convert_to_tensor=True)
similarity = util.pytorch_cos_sim(ground_truth_embedding, transcription_embedding)
return similarity.item()
The Final Word
Use torch for lightning-fast transcriptions and let's wait for ctranslate2 to implement mps backend or wait for that whisper.mojo
Written by
Anton Vice